Projection and Label Transfer#
An embedder can itself serve as a classifier, as it makes similarity judgments based on kNN. Using an embedder capable of embedding new data (retraining) allows an unknown dataset and a known dataset to be co-embedded into the same low-dimensional space. Classification and clustering can then be performed based on the shared kNN graph. If we can keep the original embedding space unchanged (keeping the initial data points at the same positions), we can project new data onto it. PCA obviously supports this reproducibility, but it is greatly affected by batch effects. Some nonlinear methods such as scVI can also support such reproducibility while simultaneously correcting for batch effects.
Although UMAP itself also supports retraining, neural network-based UMAP is less effective than traditional methods and it is difficult to select appropriate hyperparameters. We use MDE for embedding, which supports retraining well and can create constraints that keep the original data points reproducible.
[1]:
%load_ext autoreload
%autoreload 2
[2]:
import exprmat as em
# set working directory
em.setwd('../../../data')
ver = em.version()
[i] exprmat 0.2.66 / exprmat-db 0.2.66
[i] os: posix (linux) platform version: 6.8.0-90-generic
[i] loaded configuration from /home/data/yangz/.exprmatrc
[i] current working directory: /home/data/yangz/packages/exprmat/data
[i] current database directory: /home/data/yangz/packages/database (0.2.66)
[i] resident memory: 774.11 MiB
[i] virtual memory: 5.95 GiB
Preparing the Reference Atlas#
We need to perform some necessary preparations for a reference atlas, including:
Train an scVI / scANVI embedder
Obtain a suitable 2D dimensionality reduction representation at the atlas level
Once the atlas preparation is complete, please save the atlas experiment object so that it will be written to disk.
[3]:
atlas = em.load_experiment(
direc = 'expm/scrna',
load_samples = False,
load_subset = 'mono-neutro'
)
[!] samples are not dumped in the experiment directory.
[4]:
print(atlas)
annotated data of size 9754 × 19651
subset mono-neutro of size 9754 × 19651
contains modalities: rna
modality [rna]
obs : sample <cat> <c/sample> batch <cat> <c/batch> group <cat> <c> modality <cat> <c/modality>
taxa <cat> <c/taxa> barcode <o> <o> ubc <o> <o> n.umi <f64> <i> n.genes <i64> <i>
n.mito <f64> <f> n.ribo <f64> <f> pct.mito <f64> <f> pct.ribo <f64> <f>
filter <bool> <bool> score.doublet <f64> <f> score.doublet.se <f64> <f>
is.doublet <bool> <bool> qc <bool> <bool/qc> leiden <cat> <c> sc3.5 <cat> <c>
sc3.10 <cat> <c> sc3.20 <cat> <c> sc3.30 <cat> <c> cell.type <cat> <c>
kde.umap <f64> <f/kde> psbulk <cat> <o> cytotrace.score <f64> <f>
cytotrace.potency <cat> <o> cytotrace.relative <f64> <f> cytotrace.score.preknn <f64> <f>
cytotrace.potency.preknn <cat> <o> ppt.pseudotime <f64> <f> ppt.seg <cat> <o>
ppt.edge <cat> <o> ppt.milestones <cat> <o>
var : chr <cat> <c/chromosome> start <i64> <i> end <i64> <i> strand <cat> <c/strand> id <o> <o>
subtype <cat> <c/gsubtype> gene <cat> <o/gene> tlen <f64> <i/tlen> cdslen <i64> <i/cdslen>
assembly <cat> <c> uid <o> <o/ugene> vst.hvg <bool> <bool/hvg> vst.all.means <f64> <f>
vst.all.vars <f64> <f> vst.all.vars.norm <f64> <f> vst.all.hvg.rank <f32> <f>
vst.all.hvg <bool> <bool>
layers : counts <f32> <i/counts> magic <f64> <f/normal/imputed> norm <f32> <f>
obsm : cnmf.10 <df> <f/embedding/usage> diffmap <arr:f32(5)> <f/embedding>
harmony <arr:f32(35)> <f> knn <arr:i32(100)> <i/knni> knn.d <arr:f32(100)> <f/knnd>
knn.d.nn30.diffmap <arr:f32(30)> <f> knn.nn30.diffmap <arr:i32(30)> <i>
pca <arr:f64(35)> <f/embedding/pca> ppt <arr:f64(2000)> <ppt-assign>
umap <arr:f32(2)> <f/embedding> umap.diff <arr:f32(2)> <f/embedding>
varm : cnmf.10 <arr:f64(10)> <f/weights> cnmf.coef.10 <arr:f64(10)> <f/usage-coef>
pca <arr:f64(35)> <f/weights>
obsp : connectivities <csr:f32> <f/connectivity> connectivities.nn30.diffmap <csr:f32> <f>
distances <csr:f32> <f/distance> distances.nn30.diffmap <csr:f32> <f>
uns : cell.type.colors <o> cell.type_colors <o> cnmf <cnmf> cnmf.args <o>
cnmf.density.10 <cnmf-density> cnmf.dist.10 <f/connectivity> cnmf.stats <cnmf-stats>
commands <system> diffmap <o> kde.umap <kde-stats> leiden <o> leiden.colors <o>
magic.errors <magic-errors> magic.t <magic-t> markers <markers> neighbors <knn>
nn30.diffmap <knn> pca <dict> ppt <ppt> ppt.graph <o> ppt.milestones.colors <o>
ppt.pseudotime <o> ppt.root <i> ppt.seg.colors <o> sc3.10.colors <o> sc3.20.colors <o>
sc3.30.colors <o> sc3.5.colors <o> slots <system> trace <trace> umap <o> umap.diff <o>
[*] samples not loaded from disk.
[5]:
fig = atlas.rna.plot_embedding(
basis = 'umap', color = 'cell.type', annotate_style = 'text', legend = False,
figsize = (3, 3), dpi = 100, ptsize = 4, contour_plot = True
)
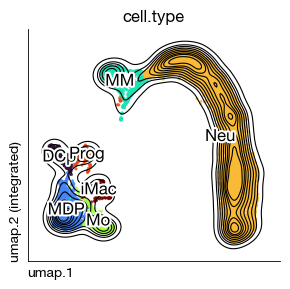
[6]:
atlas.rna.construct_atlas(
key_counts = 'counts',
key_batch = 'batch',
hvg = 'vst.all.hvg',
batch_cell_filter = 50,
# scvi model settings
scvi_n_epoch = 500,
scvi_n_latent = 30,
scvi_n_hidden = 128,
scvi_n_layers = 2,
scvi_dropout_rate = 0.1,
scvi_dispersion = 'gene',
scvi_gene_likelihood = 'nb',
scvi_latent_distrib = 'normal',
scvi_key = 'scvi',
annotation = 'cell.type',
scanvi_key = 'scanvi',
scanvi_unlabel = 'unknown',
scanvi_max_epochs = 300,
scanvi_samples_per_label = 250,
scvi_kwargs = {
'encode_covariates': True,
'deeply_inject_covariates': False,
'use_layer_norm': "both",
'use_batch_norm': "none",
},
scanvi_kwargs = {},
scanvi_train_kwargs = {
'early_stopping': True,
'early_stopping_monitor': 'elbo_validation',
'early_stopping_min_delta': 0.001,
'early_stopping_patience': 10,
},
scvi_train_kwargs = {
'early_stopping': True,
'early_stopping_monitor': 'elbo_validation',
'early_stopping_min_delta': 0.0,
'early_stopping_patience': 9,
'early_stopping_warmup_epochs': 0,
'early_stopping_mode': 'min',
'plan_kwargs': {
'reduce_lr_on_plateau': True,
'lr_patience': 8,
'lr_factor': 0.1,
}
}
)
[i] prepare count matrix of size 9754 * 1937
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
[!] 0 samples is removed due to small sample size.
[i] will train 500 epochs.
Monitored metric elbo_validation did not improve in the last 9 records. Best score: 666.272. Signaling Trainer to stop.
[i] trained scvi model saved.
[i] training scanvi model on label `cell.type`
INFO Training for 300 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Monitored metric elbo_validation did not improve in the last 10 records. Best score: 665.953. Signaling Trainer to stop.
[i] trained scanvi model saved.
[i] saving metadata of atlas as a light version.
[7]:
fig = atlas.rna.plot_multiple_embedding(
basis = 'umap', features = ['Csf1r', 'Csf3r'], ncols = 2, annotate_style = 'text', legend = False,
figsize = (5, 2.5), dpi = 100, ptsize = 4, contour_plot = False, cmap = 'turbo'
)
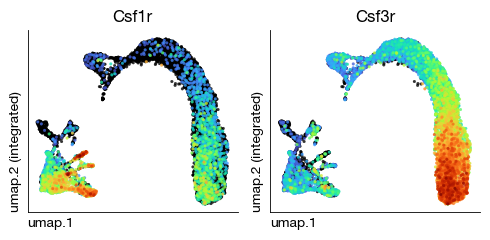
[8]:
atlas.save(save_samples = False)
[i] main dataset write to expm/scrna/subsets/mono-neutro.h5mu
Projection Dataset#
The projection dataset itself does not require much preparation to be projected onto an already loaded, prepared reference dataset. The only requirement for the projection dataset is to have the raw UMI count matrix counts.
[9]:
query = em.load_experiment(
direc = '/home/data/yangz/rna/m-ck-cd45-radiotherapy-crm/expm',
load_samples = False, load_subset = 'neutrophil'
)
[!] samples are not dumped in the experiment directory.
[10]:
print(query)
annotated data of size 2359 × 21687
subset neutrophil of size 2359 × 21687
contains modalities: rna
modality [rna]
obs : sample <cat> batch <cat> group <cat> modality <cat> taxa <cat> barcode <o> ubc <o>
n.umi <f32> n.genes <i64> n.mito <f64> n.ribo <f64> pct.mito <f64> pct.ribo <f64>
filter <bool> score.doublet <f64> score.doublet.se <f64> is.doublet <bool> qc <bool>
leiden <cat> annot <cat> time <cat> kde.time <f64> cell.type <cat> ppt.pseudotime <f64>
ppt.seg <cat> ppt.edge <cat> ppt.milestones <cat> n.umi.unspliced <f64>
n.umi.spliced <f64> velocity.self.transition <f32> root.cells <f64> endpoints <f64>
velocity.pseudotime <f64> velocity.length <f32> velocity.confidence <f64>
velocity.confidence.transition <f32>
var : chr <cat> start <i64> end <i64> strand <cat> id <o> subtype <cat> gene <o> tlen <f64>
cdslen <i64> assembly <cat> uid <o> vst.hvg <bool> vst.all.means <f64> vst.all.vars <f64>
vst.all.vars.norm <f64> vst.all.hvg.rank <f32> vst.all.hvg <bool> expressing <bool>
velocity.gamma <f32> velocity.qreg.ratio <f32> velocity.r2 <f64> velocity.genes <bool>
layers : ambiguous <f64> counts <f32> magic <f64> ms <f32> mu <f32> spliced <f64>
spliced.counts <f64> unspliced <f64> unspliced.counts <f64> variance.velocity <f32>
velocity <f32>
obsm : harmony <arr:f64(50)> knn.d.nn30 <arr:f32(30)> knn.nn30 <arr:i32(30)> pca <arr:f64(50)>
ppt <arr:f64(2000)> projection <arr:f32(2)> scanvi <arr:f32(30)> umap <arr:f32(2)>
umap.neu <arr:f32(2)> vdiff <arr:f64(10)> velocity.umap.neu <arr:f64(2)>
varm : pca <arr:f64(50)>
obsp : connectivities.nn30 <csr:f32> distances.nn30 <csr:f32>
uns : annot.colors cell.type.colors deg gsea kde.time leiden leiden.colors magic.errors magic.t
nn30 ora pca ppt ppt.graph ppt.milestones.colors ppt.pseudotime ppt.seg.colors projection
trace umap umap.neu velocity.graph velocity.graph.neg velocity.params
[*] samples not loaded from disk.
The re_embed parameter determines whether to train a new joint embedding. If set to False, the embedder will be constrained to keep the original atlas in the same position, making the new embedding visually intuitive. However, if the sample density deviation is large, the new embedding points may become extremely clustered in close proximity, failing to reveal more detailed structure.
[14]:
query.rna.project(
atlas = atlas,
atlas_modality = 'rna', # must match
atlas_embedding = 'umap',
counts_key = 'counts',
batch_key = 'batch',
key_query_latent = 'scanvi',
scanvi_unlabel = 'unknown', # must match
scvi_epoch_reduction = 3,
predict_labels = 'cell.type',
key_added = 'projection',
# mde settings
re_embed = False, # whether to re-embed the data:
# set re-embed to False will preserve the atlas embedding as is, and fit the
# query dataset directly onto it.
)
[i] preparing query data ...
INFO File expm/scrna/scanvi/mono-neutro/model.pt already downloaded
INFO Found 91.68817759421786% reference vars in query data.
[i] constructing query model for batch correction ...
INFO File expm/scrna/scanvi/mono-neutro/model.pt already downloaded
[i] will automatically train 133 epochs ...
INFO Training for 133 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
`Trainer.fit` stopped: `max_epochs=133` reached.
[i] getting latent representations ...
[15]:
print(query)
annotated data of size 2359 × 21687
subset neutrophil of size 2359 × 21687
contains modalities: rna
modality [rna]
obs : sample <cat> batch <cat> group <cat> modality <cat> taxa <cat> barcode <o> ubc <o>
n.umi <f32> n.genes <i64> n.mito <f64> n.ribo <f64> pct.mito <f64> pct.ribo <f64>
filter <bool> score.doublet <f64> score.doublet.se <f64> is.doublet <bool> qc <bool>
leiden <cat> annot <cat> time <cat> kde.time <f64> cell.type <cat> <c>
ppt.pseudotime <f64> ppt.seg <cat> ppt.edge <cat> ppt.milestones <cat>
n.umi.unspliced <f64> n.umi.spliced <f64> velocity.self.transition <f32> root.cells <f64>
endpoints <f64> velocity.pseudotime <f64> velocity.length <f32> velocity.confidence <f64>
velocity.confidence.transition <f32>
var : chr <cat> start <i64> end <i64> strand <cat> id <o> subtype <cat> gene <o> tlen <f64>
cdslen <i64> assembly <cat> uid <o> vst.hvg <bool> vst.all.means <f64> vst.all.vars <f64>
vst.all.vars.norm <f64> vst.all.hvg.rank <f32> vst.all.hvg <bool> expressing <bool>
velocity.gamma <f32> velocity.qreg.ratio <f32> velocity.r2 <f64> velocity.genes <bool>
layers : ambiguous <f64> counts <f32> magic <f64> ms <f32> mu <f32> spliced <f64>
spliced.counts <f64> unspliced <f64> unspliced.counts <f64> variance.velocity <f32>
velocity <f32>
obsm : harmony <arr:f64(50)> knn.d.nn30 <arr:f32(30)> knn.nn30 <arr:i32(30)> pca <arr:f64(50)>
ppt <arr:f64(2000)> projection <arr:f32(2)> scanvi <arr:f32(30)> <f/embedding>
umap <arr:f32(2)> umap.neu <arr:f32(2)> vdiff <arr:f64(10)> velocity.umap.neu <arr:f64(2)>
varm : pca <arr:f64(50)>
obsp : connectivities.nn30 <csr:f32> distances.nn30 <csr:f32>
uns : annot.colors cell.type.colors deg gsea kde.time leiden leiden.colors magic.errors magic.t
nn30 ora pca ppt ppt.graph ppt.milestones.colors ppt.pseudotime ppt.seg.colors
projection <projection> trace umap umap.neu velocity.graph velocity.graph.neg
velocity.params commands <system> slots <system>
[*] samples not loaded from disk.
[16]:
query['rna'].uns['projection']
[16]:
| batch | annotation | x | y | |
|---|---|---|---|---|
| distal:2 | b1 | Neu | 10.347707 | -3.442766 |
| distal:3 | b1 | Neu | 9.640812 | 0.758175 |
| distal:4 | b1 | Neu | 9.359683 | 7.425988 |
| distal:8 | b1 | Neu | 10.497822 | -0.685123 |
| distal:9 | b1 | Neu | 9.852562 | 7.167100 |
| ... | ... | ... | ... | ... |
| normal:4657 | b3 | Prog | -4.098613 | 2.992019 |
| normal:4658 | b3 | Neu | 8.916982 | 5.135273 |
| normal:4660 | b3 | Neu | 12.197971 | 1.754336 |
| normal:4661 | b3 | Neu | 7.219741 | 10.696441 |
| normal:4662 | b3 | Neu | 9.900393 | 0.083080 |
9754 rows × 4 columns
[17]:
fig = query.rna.plot_multiple_embedding(
basis = 'umap.neu', features = ['Csf1r', 'Csf3r', 'cell.type'], ncols = 3,
annotate_style = 'text', legend = False, annotate_fontsize = 8,
figsize = (7.5, 2.5), dpi = 100, ptsize = 10, contour_plot = False, cmap = 'turbo'
)
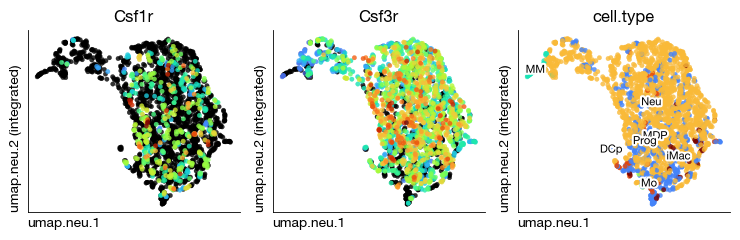
[19]:
# re-embed = False
fig = query.rna.plot_projection(
color = 'S100a9', cmap = 'turbo',
figsize = (3, 3), dpi = 100, projection_key = 'projection',
contour_plot = False,
contour_fill = False,
contour_levels = 3,
contour_bw = 2,
# atlas background
background = 'annotation',
annotate = True, annotate_fontsize = 9,
)
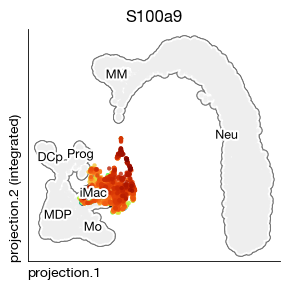
[ ]:
query.save(save_samples = False)